Python 3.11 では、新しい正規表現として (?>...)、*+、 ++、 ?+、{m,n}+ が追加されました。
(?>...) はアトミックグループと呼ばれる正規表現で、*+、 ++、 ?+、{m,n}+ はそれぞれ既存の *、+、?、{m,n} にアトミックグループの機能をもたせた正規表現です。
従来の.*a のような正規表現は、なるべく長い文字列とマッチするようになっています。たとえば、正規表現 .*a は a で終わる任意の文字列にマッチしますが、文字列 11a22a33abc とマッチすると、11a や 1122a ではなく、一番長い 11a22a33a とマッチします。
import re
re.match(r".*a", "11a22a33abc")
正規表現は、できるだけ長い文字列とマッチできるように、まず最初に一番長い文字列とマッチできないか試してみます。マッチに失敗すると、もうちょっと短い文字列で試してみます。マッチが成功するまでこれを繰り返し、可能なすべての組み合わせを順番に試します。
通常の正規表現は、このような仕組みでできるだけ長い文字列とマッチしようとします。しかし、アトミックグループとして指定した部分の正規表現では、一度マッチが成功したらその後はもう繰り返しません。繰り返しが必要な場合にはマッチ全体が失敗します。
たとえば、正規表現 .*a をアトミックグループを使って (?>.*)a と書くと、文字列 11a22a33abc とマッチしなくなります。
import re
print(re.match(r"(?>.*)a", "11a22a33abc"))
正規表現 (?>.*) の部分は最初に 11a22a33abc 全体とマッチし、その次の正規表現 a はマッチできる文字がないため、マッチ失敗となります。
アトミックグループがなければ正規表現 .* がマッチする範囲を変更してマッチするまで繰り返しますが、アトミックグループ内の文字列は一度しかマッチしないため、他の候補を試さずに終了してしまいます。
通常の正規表現は可能な限りマッチできるように、色々なパターンを試します。しかし、アトミックグループは、最初に見つかったパターンだけを試して、そのパターンがダメならすぐにあきらめる、という指定になります。
import re
print(re.match(r".+a", "111a2"))
この正規表現は、任意の文字列すべてにマッチする ".+" と、文字 a だけにマッチする "a"に分けられます。
正規表現と文字列をマッチするとき、まず最初の正規表現 .+ で対象の文字列とマッチすると、文字列 111a2 全体にマッチします。続けて正規表現 a でマッチしますが、このとき、文字列 111a2 はもう最後まで使われているのでマッチする文字がなく、エラーとなります。
すると、もう一度最初の正規表現 .+ に戻り、今度は .+ は 111a2 全体ではなく、一文字縮めた 111a にマッチします。続けて正規表現 a でマッチしますが、このとき、文字列 111a2 は 111a までマッチしていて残りは "2" となっており、a と 2 はマッチしないので今度もまたエラーとなります。
そこでもう一度度最初の正規表現 .+ に戻り、今度は .+ がもう一文字縮めた 111 にマッチします。次に正規表現 a でマッチしますが、このとき、文字列 111a2 は 111 までマッチしていて残りは "a2" ですので、今度は a がマッチしてマッチング成功、となります。
| 試行回数 | ".*" にマッチする文字列 | "a" にマッチする文字列 | 結果 |: ----- :|: -------------------- :|: ------------------- :| :---:| | 1回目 | 111a2 | (なし) | 失敗 | 2回目 | 111a | 2 | 失敗 | 3回目 | 111 | a | 成功
Pythonの re のようなタイプの正規表現エンジンは、マッチングに成功するまで、正規表現を後戻りしながら一致する文字列を探索します。こういう動作のことを バックトラック と呼びます。
バックトラックの問題点¶
次のように、数字を数字以外の任意の文字でつないだ文字列全体にマッチする正規表現を考えてみましょう。
12,3456.78/9
まず任意の桁数の数字で始まりそのあとに任意の文字が続くので、この部分の正規表現は \d+. となります。 \d+. が繰り返され、最後には数字列で終わりますから、全体は ^(\d+.)+\d+$ となります。簡単ですね。(←なんだか仕様的に怪しい気もしますが、ここでは無視して先に進めましょう…)
import re
re.match(r"^(\d+.)+\d+$", "12,3456.78/9")
試しに、この正規表現をもっと長い文字列とマッチして処理時間を計測してみましょう。
$ python3.11 -m timeit -s "import re" 're.match(r"^(\d+.)+\d+$", "12."*1000+"12")'
20000 loops, best of 5: 10.8 usec per loop
長い文字列とのマッチでもとても高速です。問題ないですね。
しかし、マッチが失敗するような文字列を与えるとどうなるでしょう?
$ python3.11 -m timeit -s "import re" 're.match(r"^(\d+.)+\d+$", "12"*1000+"12@")'
こんどはいくら待っても処理が終了しません。長い時間がかかっているようです。文字列の長さを変化させて、処理時間がどのぐらいかかっているか調べてみましょう。
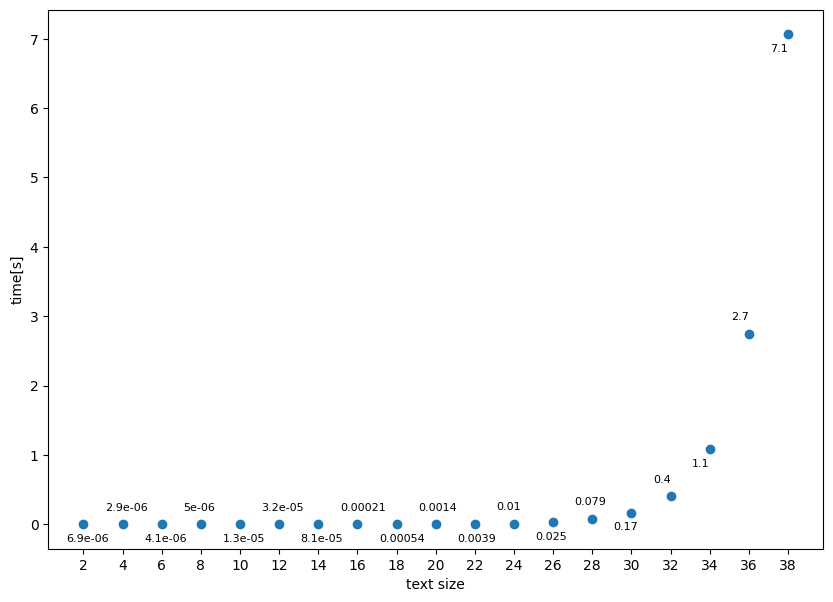
ダメですね。ダメです。これはダメなやつです。末尾が数字ではなく、正規表現のマッチングに失敗するケースでは、文字列の長さに応じて非線形に処理時間が長くなっています。
このケースでは、一番最後の文字でマッチングに失敗すると、その前の正規表現でバックトラックを行います。しかし、それでもまた最後には失敗するので、また一つ前に戻ってバックトラックします。しかしそこでもまた失敗するのでまたバックトラックが発生し……と、多くのバックトラックが発生します。最終的にマッチが失敗するまでにすべての可能な組み合わせを試すため、非常に長い時間がかかっています。
このように処理時間が長い正規表現をWebサービスなどで使用してしまうと、悪意のあるリクエストでわざと時間のかかるデータを送信され、サービスが中断してしまう危険性もあります。このような、正規表現を利用したDoS攻撃を、ReDoS といいます。
アトミックグループ¶
この正規表現でReDosが発生しないようにするには、バックトラックを禁止するという方法が考えられます。^(\d+.)+\d+$ という正規表現の場合、失敗する文字列ではどれだけバックトラックしても結局は失敗するので、バックトラックは時間の無駄にしかなりません。
Python3.11で追加された正規表現 (?>...) は アトミックグループ と呼ばれ、グループ内では前述のバックトラックを禁止します。先ほどの正規表現 .+a にアトミックグループを指定して r"(?>.+)a" とすると、文字列 111a2 にマッチしません。
import re
print(re.match(r"(?>.+)a", "111a2"))
正規表現 (?>.+) は最初に "111a2" 全てにマッチして、続く a のマッチに失敗します。本来ならバックトラックが発生して .+ と "111a" をマッチさせて処理を続行するのですが、(?>.+) でバックトラックを禁止しているので、そのままマッチング失敗となります。
問題の正規表現 ^(\d+.)+\d+$ も、アトミックグループを利用して ^(?>\d+.)+\d+$ とすれば、文字列の末尾以外ではバックトラックが発生しません。したがって、末尾でマッチングに失敗しても不要な処理が発生しません。
$ python3.11 -m timeit -s "import re" 're.match(r"^(?>\d+.)+\d+$", "12"*1000+"12@")'
20000 loops, best of 5: 10.7 usec per loop
先ほどと違い、文字列の末尾でマッチに失敗すると即座に処理を終了するため、DoSなどの攻撃を受けなくなっています。
Possessive指定子¶
Greedyな指定子 *、+, ?, {m,n} に対応する、バックトラックを行わない指定子 *+, ++, ?+, {m,n}+ も追加されています。このような指定子を、Possessive指定子と呼びます。
Possessive指定子は、Greedyな指定子とアトミックグループを組み合わせて記述することもできます。
| Greedy | Possessive | アトミックグループ | 意味 |
|---|---|---|---|
| x* | x*+ | (?>x*) | 0回以上の繰り返し |
| x+ | x++ | (?>x+) | 1回以上の繰り返し |
| x? | x?+ | (?>x?) | 0または1回の繰り返し |
| x{m,n} | x{m,n}+ | (?>x{m,n}) | m回からn回の繰り返し |